TigerFans: Hot/Cold Path Architecture
How we achieved 5x throughput by separating hot and cold data paths
TL;DR
PostgreSQL in the critical path limited our throughput to ~150 ops/s (Phase 1: Reservations), despite TigerBeetle and Redis being capable of much more. By separating “hot” (ephemeral, high-frequency) data into Redis and “cold” (durable, archival) data into PostgreSQL, we achieved 865 ops/s—a 5.8x improvement over the PostgreSQL-only baseline. Further optimization with auto-batching pushed this to 977 ops/s.
Key insight: Not all data needs to be durable immediately. Payment sessions are ephemeral; only successful orders need PostgreSQL durability.
Credit: Rafael Batiati’s original architectural insight led to this breakthrough—suggesting Redis for payment sessions and PostgreSQL only for durable orders.
PostgreSQL as a Bottleneck
Initial Architecture
Our first implementation asked PostgreSQL to handle three responsibilities: payment sessions that tracked orders during checkout, final order records for long-term storage, and idempotency keys that prevented webhook replays. Under load, we hit a ceiling at approximately 150 operations per second.
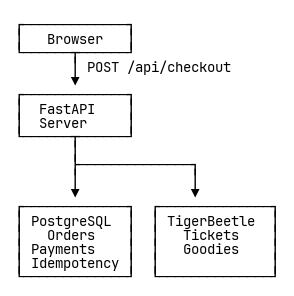
Why It Was Slow
ACID guarantees require disk synchronization—every write triggers a Write-Ahead Log flush. Each checkout touched PostgreSQL four times: save payment session, check idempotency, write idempotency key, create order. Four fsyncs per request. Even with aggressive tuning (disabling synchronous commits—risky, expanding shared buffers to 2GB, connection pooling), disk I/O limited throughput to approximately 150 ops/s.
The Journey to Hot/Cold Separation
The Redis Experiment
After analyzing the sequence diagram and seeing PostgreSQL hit 2-4 times per request, I started questioning our architecture. Do we really need a relational database when we don’t do anything particularly relational with it? We’re basically just storing orders and idempotency keys.
I implemented Redis as a complete DATABASE_URL replacement, making the system support three swappable backends: SQLite, PostgreSQL, or Redis. Same interface, different storage. I replaced ALL of PostgreSQL with Redis—not just sessions, but everything.
Running benchmarks with Redis in everysec fsync mode yielded impressive results:
- Phase 1 (Reservations): 930 ops/s (6x improvement!)
- Phase 2 (Webhooks): 450 ops/s (3.4x improvement!)
The numbers were exciting. But there was a problem: Redis in everysec mode could lose up to 1 second of orders on crash. The faster Redis gets, the worse this becomes. I had replaced ALL of PostgreSQL with Redis, including the durable orders. Not acceptable, even for a demo.
Rafael’s Hot/Cold Path Compromise
I shared these impressive benchmark results (and the durability concern) with Rafael. His response brought the architectural insight that transformed the system: separate ephemeral session data from durable order records. The hot/cold path compromise.
This was the hot/cold path insight—a compromise between speed and durability. Rafael’s suggestion was a response to my Redis experiment: instead of replacing ALL of PostgreSQL with Redis (which sacrificed durability), use Redis ONLY for payment sessions (hot path), NOT for orders (cold path). Orders must go to PostgreSQL for durability.
Mind. Blown. What a great idea!
This insight reframed the entire problem: not all writes need durability. If a payment session is lost due to a server crash, the user gets redirected to the payment provider, the webhook can’t find the session, the user sees an error and retries. No money is lost, no tickets are double-sold. TigerBeetle handles the resource accounting (tickets and goodies) with full durability. PostgreSQL only needs to durably record successful outcomes.
Hot/Cold Path Separation
A New Architecture
The new architecture treats each data type according to its lifecycle. Redis became our hot path: payment sessions that exist for minutes, not months, and idempotency keys that matter for hours, not years. These don’t need PostgreSQL’s durability guarantees—if they’re lost in a crash, TigerBeetle’s accounting remains consistent and users simply retry.
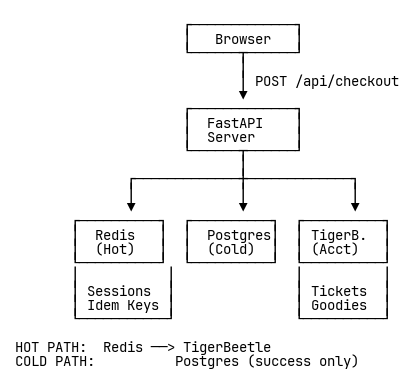
PostgreSQL became our cold path, storing only what must survive forever: completed order records for customers and historical data for reporting. By moving ephemeral coordination data out of PostgreSQL, we reduced its write load by 75% while making the hot path 20x faster.
Data Placement
Redis handles payment sessions (ephemeral, under 5 minutes), idempotency keys (expire after 24 hours), and recent payment activity for UI display. PostgreSQL stores orders as durable records and provides historical reporting data. TigerBeetle manages the accounting: ticket accounts for Class A and Class B tickets, goodie accounts, pending transfers for holds, and posted transfers for final allocations.
This separation isn’t about what the data represents—it’s about when it matters. The same logical entity (an order) has different storage needs at different times. During checkout, it’s hot data living in Redis. After payment succeeds, it becomes cold data archived in PostgreSQL.
Performance Analysis
Benchmark Setup
- Hardware: AWS c7g.xlarge (4 vCPU, 8 GB RAM, ARM64)
- Load: 30 concurrent clients
- Test: 1,000 checkouts with payment success
- Fail rate: 0% (all succeed for comparison)
Results

Improvement (PostgreSQL-only → TigerBeetle+Redis):
- Throughput: ~150 ops/s → ~865 ops/s (5.8x improvement)
- Latency improved dramatically
The hot/cold architecture provided the foundation. Further optimization with auto-batching pushed throughput to 977 ops/s, with batching efficiency averaging 5-6 transfers per TigerBeetle request.
Where Time Was Spent
PostgreSQL-only (per request):
- PostgreSQL accounting operations: significant disk I/O overhead
- Payment session storage (save/get): disk writes
- Idempotency checking: database queries
- Python overhead
Hybrid architecture (per request):
- TigerBeetle accounting operations: ~3ms (in-memory, batched)
- Payment session storage (Redis): ~1ms (in-memory)
- Idempotency checking (Redis): atomic Lua scripts
- Database order writes (cold path): ~15ms (async, only on success)
- Python overhead
The key improvement: payment session storage dropped from disk writes to in-memory operations. PostgreSQL writes moved to the cold path, happening only for successful orders rather than on every checkout attempt. The hot path runs primarily in memory (Redis + TigerBeetle), with PostgreSQL providing durable archival only when needed.
Trade-offs and Failure Modes
The Trade-offs
The hot/cold architecture delivered a 5.8x throughput improvement (~150 → 865 ops/s) by offloading ephemeral data from PostgreSQL to Redis. Redis’s in-memory operation reduced session storage latency, auto-expiring keys eliminated cleanup jobs, and PostgreSQL could focus solely on durable archival records.
But these gains came with trade-offs. Payment sessions and idempotency keys are no longer durable—a Redis crash loses in-flight coordination data. We also doubled our operational complexity: two data stores to monitor, two failure modes to plan for, and debugging that spans both systems.
We judged this acceptable because TigerBeetle provides the durability guarantee that matters: tickets can’t be double-sold, and money can’t be lost. Redis crashing only loses coordination state, which users recover from by retrying checkout. The small inconsistency window—milliseconds between webhook receipt and PostgreSQL commit—poses minimal risk compared to the performance gains.
Failure Scenarios
Redis crash: Payment sessions are lost, users at the payment provider see “session not found” errors on webhook callbacks, TigerBeetle pending transfers timeout after 5 minutes and release tickets back to inventory automatically. No money lost, no tickets double-sold. Recovery: restart Redis, users retry checkout, system recovers automatically. This is acceptable because payment sessions are designed to be ephemeral, and TigerBeetle provides the durability guarantee for tickets.
Split-brain scenario (order in PostgreSQL but idempotency key lost in Redis): Webhook replay creates duplicate order, caught by unique constraint on order ID. IntegrityError handled gracefully, no double-fulfillment. The database serves as truth when Redis state is lost.
The Durability Window
Between webhook success and PostgreSQL commit (under 10ms), there’s a brief durability window where the order record exists only in Redis (volatile). If the system crashes during this window, the customer has paid and the ticket is allocated in TigerBeetle (both durable), but the order record is lost.
This is not eventual consistency—it’s a durability gap where state is consistent but not fully persisted. However, the TigerBeetle transaction has already committed—the ticket is properly allocated and accounted for, no double-booking possible. If the user rightfully complains, it’s safe to issue their ticket manually since TigerBeetle guarantees the inventory is correct. Payment provider webhook replay can automatically recover the order using idempotency keys. PostgreSQL provides customer records, not correctness.
Conclusion
This pattern applies far beyond TigerFans. Anytime you have high-frequency coordination data plus low-frequency durable records, consider hot/cold path separation.
Thank you, Rafael, for the architectural insight about hot/cold path separation—the perfect compromise that unlocked the breakthrough.
Related Documents
Full Story: The Journey - Building TigerFans
Overview: Executive Summary
Technical Details:
- Resource Modeling with Double-Entry Accounting
- Auto-Batching
- The Single-Worker Paradox
- Amdahl’s Law Analysis
Resources: