TigerFans: The Single-Worker Paradox
Why one worker outperforms multiple workers in batch-oriented architectures
“More workers, lower throughput—wait, what?” — The moment we discovered the single-worker paradox
TL;DR
Conventional wisdom says “more workers = more throughput.” With TigerFans, we discovered the opposite: one worker performs better than multiple workers on a multi-core machine.
The reason: Our architecture depends on batching for performance. Multiple workers fragment requests across event loops, creating smaller batches. One worker consolidates all requests into larger, more efficient batches.
Performance (8 vCPU machine):
- 1 worker: 977 tickets/sec, average batch size 5.3
- 2 workers: 966 tickets/sec, average batch size 3.9
- 3 workers: 770 tickets/sec, average batch size 2.9
- Result: Single worker is 21% faster than 3 workers
The paradox: Adding resources (workers) decreased performance because it disrupted the optimization that mattered most—batching.

Why More Workers Usually Helps
Most web applications benefit from multiple workers. A load balancer distributes requests across workers, each running on a separate CPU core. Each worker processes requests independently—one handles user 42, another handles user 99, no coordination needed. The result is near-linear scaling: 4 workers deliver approximately 4x the throughput of 1 worker.
This works because most web apps are request-bound, not batch-bound. Each request completes independently without needing to coordinate with other concurrent requests.
Why TigerFans Is Different
TigerFans’ performance depends on batching database operations:
@app.post("/api/checkout")
async def checkout(...):
# This goes through LiveBatcher
result = await batcher.submit([transfer])
# Batched with other concurrent transfers
The LiveBatcher collects concurrent requests and packs them into large batches:
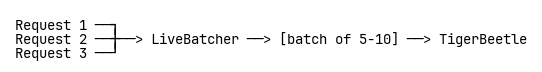
Key insight: The larger the batch, the better the performance. TigerBeetle can handle up to 8,190 operations per request.
Single Worker Architecture
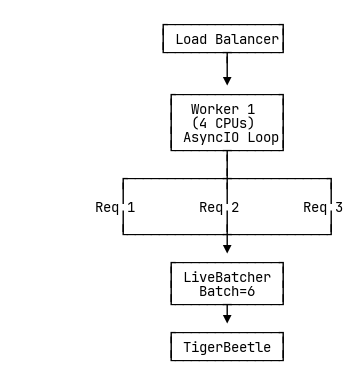
What happens:
- All concurrent requests hit the same event loop
- LiveBatcher sees all requests together
- Packs them into a single large batch
- Batch size: 5-6 transfers per request
Multi-Worker Architecture
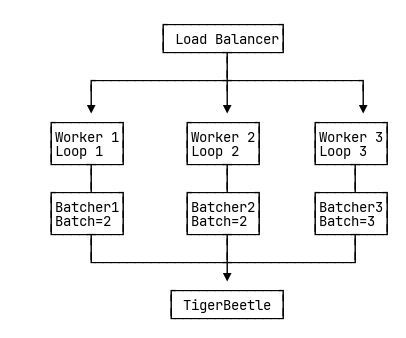
What happens:
- Requests distributed across workers by load balancer
- Each worker has its own event loop
- Each worker has its own LiveBatcher instance
- Batchers compete for TigerBeetle access
- TigerBeetle processes these smaller batches sequentially (no parallel benefit)
- Batch size: 2-3 transfers per request (fragmented!)
Discovery Through Measurement
Initial Testing
For this testing, I upgraded to c7g.2xlarge (8 vCPU, 16 GB RAM) to see how the system would scale with multiple workers.
After implementing LiveBatcher, we tested with the standard multi-worker configuration:
# Standard practice: 1 worker per CPU pair
$ uvicorn tigerfans.server:app --host 0.0.0.0 --port 8000 --workers 2
Load test (1,000 reservations):
With TigerBeetle + Redis (optimal configuration):
Total: 1,000 OK: 1,000
Throughput: 966 ops/s
🔍 Average batch size: 3.9
Hmm, not as good as expected given the available CPUs.
The Single-Worker Test
Out of curiosity, I tried a single worker on the same 8 vCPU machine:
# Counterintuitive: just 1 worker on 8 CPUs
$ uvicorn tigerfans.server:app --host 0.0.0.0 --port 8000 --workers 1
Same load test:
Total: 1,000 OK: 1,000
Throughput: 977 ops/s
🔍 Average batch size: 5.3
Wait, what? Single worker is faster with better batch consolidation!
Testing with 3 Workers
$ uvicorn tigerfans.server:app --host 0.0.0.0 --port 8000 --workers 3
Same load test:
Total: 1,000 OK: 1,000
Throughput: 770 ops/s (21% slower than 1 worker!)
🔍 Average batch size: 2.9
The degradation becomes dramatic with more workers.
Batch Size Explains It
Looking at the batch size metrics:
- 1 worker: Average batch size 5.3
- 2 workers: Average batch size 3.9
- 3 workers: Average batch size 2.9
The bottleneck wasn’t CPU—it was batching efficiency!
With multiple workers, requests were fragmented across event loops: Each worker’s LiveBatcher only saw a fraction of the concurrent load, resulting in smaller batches. Since TigerBeetle processes these batches sequentially, fragmenting into smaller batches across workers provided no parallel benefit—just overhead.
Why Single Worker Wins
Amdahl’s Law Explains the Paradox
This is Amdahl’s Law in action: when batch fragmentation increases the effective serial portion of request processing, adding more workers hurts performance. The serial overhead per request dominates, and consolidating all requests into a single worker’s batcher maximizes batch sizes and throughput.
For the detailed Amdahl’s Law analysis including component timings, theoretical predictions, and the mathematical framework explaining why batch consolidation outperforms parallelism, see Amdahl’s Law Analysis - The Batching Bottleneck.
TigerBeetle Performance vs Batch Size
TigerBeetle’s throughput scales superlinearly with batch size because of fixed overhead per request: network round-trips, serialization, consensus protocol coordination, and disk I/O are amortized across all operations in a batch.
Larger batches are dramatically more efficient—the same network round-trip and consensus round can process many more operations. This explains why single worker (batch size 5.3) outperforms 3 workers (batch size 2.9) by 21%: the consolidation effect matters more than parallel processing.
Conclusion
Running TigerFans with 1 worker on an 8 vCPU machine delivered 21% better throughput than running with 3 workers (977 vs 770 ops/s). Batch sizes dropped from 5.3 to 2.9 when fragmented across workers.
The lesson: conventional wisdom fails when batching efficiency matters more than parallel processing. For batch-bound architectures, consolidation beats parallelism.
Related Documents
Full Story: The Journey - Building TigerFans
Overview: Executive Summary
Technical Details:
- Resource Modeling with Double-Entry Accounting
- Hot/Cold Path Architecture
- Auto-Batching
- Amdahl’s Law Analysis
Resources: